This was my ARENA 7.0 capstone project, done in collaboration with Marta Emili García Segura and with very helpful feedback from Xavier Poncini at Simplex. We replicated and extended Shai et al. (2024), which asks whether transformer language models encode belief states in their residual stream, that is, probability distributions over the hidden states of whatever process generated the input.
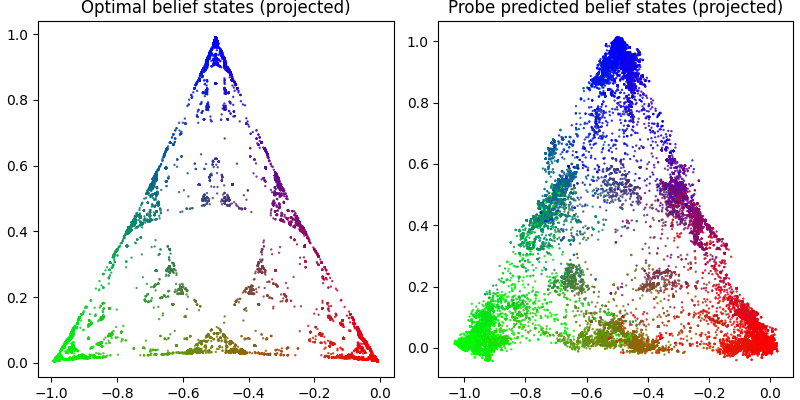
To test this, we trained a small transformer on sequences sampled from a Hidden Markov Model called Mess3 that exhibits a particularly funky, fractal belief geometry. At each position in a sequence, there is an optimal Bayesian posterior over which hidden state you are most likely in given everything you have seen so far. These belief states trace out a self-similar fractal geometry in the probability simplex as more tokens are observed. The question is whether this geometry shows up in the transformer's internals. We trained a linear probe on the residual stream activations and found that it recovers the fractal simplex structure with high fidelity, which is consistent with the original paper.
The more interesting part was the extension. A linear probe only shows correlation, not causation. To test whether the encoded belief geometry is actually being used for prediction, we trained an autoencoder to learn an invertible mapping between the residual stream and belief space, then used it to inject counterfactual beliefs directly into the model's activations mid-forward-pass. If you inject a belief corresponding to a different sequence context, the model's next-token predictions shift away from what is optimal for the original sequence and toward what is optimal for the counterfactual one. The crossover is clean and consistent across belief sources, which gives reasonable evidence that the representation is causally upstream of prediction and not just a passive byproduct.
Code, trained checkpoints, and full write-up are in the repository.