Update 11/14/23: Notion just launched Q&A, an AI-powered feature that performs many of the same tasks that Stevens does. It’s personally very validating to see a successful company like Notion building in the same direction as I’ve been thinking and prototyping!
Stevens is my personal AI assistant.
But first…
Some context on my personal knowledge base
For over three years, I’ve built and curated a personal knowledge base (PKB) on Notion. It holds a wide variety of useful external resources, including articles and books I’ve read, people and organizations I’m in touch with or whose work I follow, and a set of tags and places that connect it all together and provide additional context. Most importantly, it hosts a series of databases where I structure my own work and knowledge: a journal where I (try my best to) write every day, interconnected bits of distilled knowledge that I call “Dots”, and a work diary where I organize my personal work into sprints: chunks of work one to two weeks long where I advance my research and personal projects towards specific short-term goals I lay out in advance.
I am by no means a “Tools for Thought” maximalist. As the meme below illustrates, these tools can easily become ends in and of themselves, obscuring the actual projects we want to work on and the knowledge we want to gain behind layers of process and gardening. I often ask myself how different the outcome of a specific project -say, Rambla– would be if I used the lowest-overhead tool, like a simple to-do list, to structure my work, instead of investing so much of my time on building my personal knowledge base and keeping it clean and updated. The answer is often humbling.
However, I do find that the value of my PKB i) often comes from the building and gardening itself, which helps me absorb and structure information, much like note-taking during a lecture helps the information sink in regardless of how you use the notes later on; and ii) accrues over time: three years into this journey, it often surfaces people, articles and distilled nuggets of wisdom that would have otherwise been lost. The prospect of revisiting my thoughts and work ten years from now with this level of structure and granularity has reassured me in the long-term investment that is my knowledge base.
An interesting corollary to this reflection is that the perfect knowledge base for me doesn’t exist—yet. Notion is an incredibly powerful and flexible platform to store and structure information and work, but there’s a lot of room for improvement when it comes to browsing and surfacing this information at the right time.
I think of Notion as a backend. It allows me to define a schema for the information I work with: the properties for each data entity, their types and allowed values, and the relations between them. The Notion dashboard offers me a more interactive and abstract way to create and edit this schema on the fly, some basic automations to input information (templates, the web clipper), and a flexible albeit rudimentary ability to decouple data model and view. For example, I can generate two different views of my People database, one using the Gallery view to be able to browse contacts visually, and one using the Kanban view filtered by a certain tag to easily organize a sprint where I might need to speak to many people about a given topic.
The main limitation of this interaction paradigm is that I often feel like I’m literally browsing the database schema. My needs as a user often involve interacting with the data in my knowledge base in a much more abstract way. I’m planning a trip to Iceland—what articles should I read? What journal entries are relevant? Of course, the podcast episode I saved about the settling of Iceland in the Middle Ages is an easy choice, and one that I can find by simply typing “Iceland” in the search box, but what about that journal entry I wrote in 2021, during a volcanic eruption in my hometown of the Canary Islands, about the raw destructive/creative duality of volcanoes? I’d like to revisit that before I travel to one of the most volcanically active places in the world.
Tools like Obsidian do a much better job of allowing users to navigate interconnected pieces of information and uncover this kind of second-degree relations. However, I find that it’s lacking in data structuring capabilities for my particular use case, and in overall design. I’d rather use Notion as a powerful backend that helps me structure my own thoughts as I garden it, and build my own frontends, capitalizing on the increasingly powerful and accessible tools for text processing and visual interaction.
Stevens
Stevens is a first step in this direction. I envision him as my AI butler and librarian, and named him after the main character in Kazuo Ishiguro’s novel The Remains of the Day. He understands the way I think, has access to all the information I’ve stored, knows what I’m working on and provides helpful resources from my library, or even external resources to help me in my projects. He is capable of answering vague questions with specific answers that connect to items in my knowledge base. He helps me keep my library clean, organized and densely connected, and helps me navigate the shortcomings of the particular and circumstantial implementation of the backend, like Notion’s difficulty surfacing second-degree connections. He can remind me to journal on a daily basis (with an awareness of my current streak), send me weekly digests summarizing the ideas I’ve been exploring across articles I read, journal entries, work diary logs, quick capture notes, person/company/place entities, suggest further reading and identify common themes. Basically, he helps me achieve the goal of my knowledge base: letting my mind do what it does best—analysis, synthesis, curiosity and creativity—while outsourcing the cognitive load of memory and retrieval to a more trustworthy medium.
Retrieval-Augmented Generation
In this first implementation, Stevens is a Telegram bot that uses hybrid retrieval-augmented generation (RAG). I built him using LangChain and Chroma. Whenever I ask him a question, he runs two LLM chains: retrieval and generation. The retrieval chain finds relevant documents in my knowledge base, and the generation chain uses those documents to write a response.
The retrieval chain begins by generating a query string based on my input, and then uses that query in two separate searches. The first search uses OpenAI text embeddings to place the query in a high-dimensional space where text strings are closer together the more semantically similar they are. All the documents in my knowledge base (e.g. articles, journal entries, tags, companies, places) are also cut into small chunks and embedded into this space, updated every hour, allowing the first search to retrieve relevant documents by finding the ones closest to the query in the embedding space. The second search uses the BM25 algorithm to retrieve documents that are similar to the query based on literal text similarity, as opposed to the semantic similarity captured by the embeddings. Combining both searches (hence the term hybrid RAG) allows a wider variety of relevant documents to be retrieved.
The generation chain receives the relevant documents and uses them to produce an answer to my question. The metadata for each document includes its relations to other documents, providing the generation chain with context about second-degree connections.
Enabling second-degree connections
I had to introduce a little workaround in order to make sure Stevens could capture second-degree connections. Certain types of documents, like Places and Tags, usually only contain metadata—for example, the document “Iceland” holds no page content, and only contains metadata linking it to other documents, including articles but also Tags, like “Volcanoes”. Other types of documents, like the journal entry where I reflected on the creative and destructive nature of volcanoes, hold the content of the entry itself as well as metadata linking them to other documents—for example, the journal entry would also be linked to the Tags document “Volcanoes”.
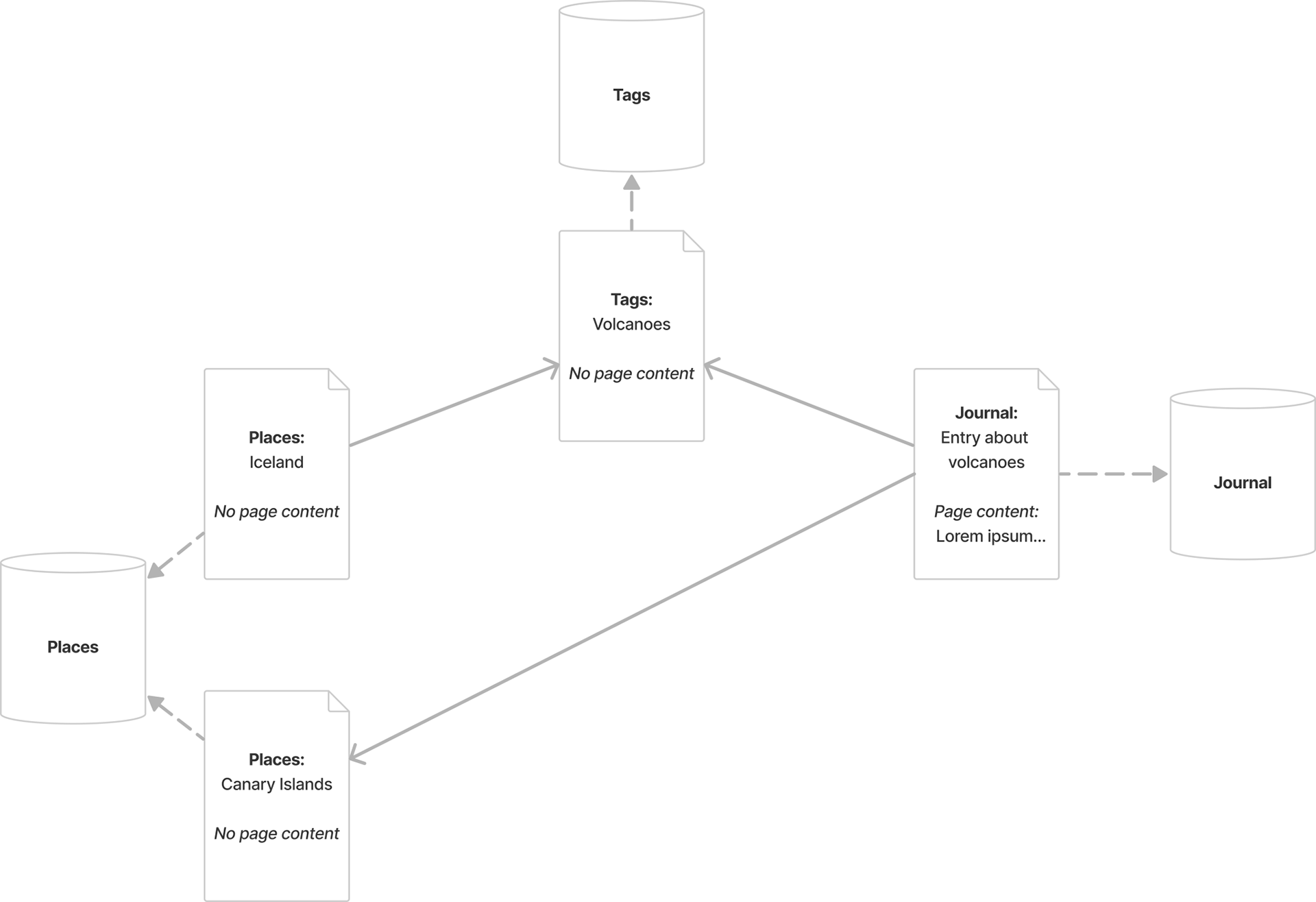
One of the limitations of RAG, at least for this use case, is that it only searches page content and not metadata. In this vanilla approach, if I asked Stevens “I’m traveling to Iceland – what should I reread from my knowledge base?”, it would generate the query string “Iceland”, which in turn would return the Places document titled “Iceland” (in orange below). When passing this document to the retrieval chain, its metadata would include its relation to the Tags document “Volcanoes” (in red below), causing the final response to the user to recommend checking out the “Volcanoes” page. This isn’t great: it could have been accomplished by simply typing “Iceland” into the search box, going to the first result, which is the page titled “Iceland”, and finding a list of related pages. The document we actually want to suggest, the journal entry about volcanoes (in blue below), simply isn’t available to the generation chain as additional context.
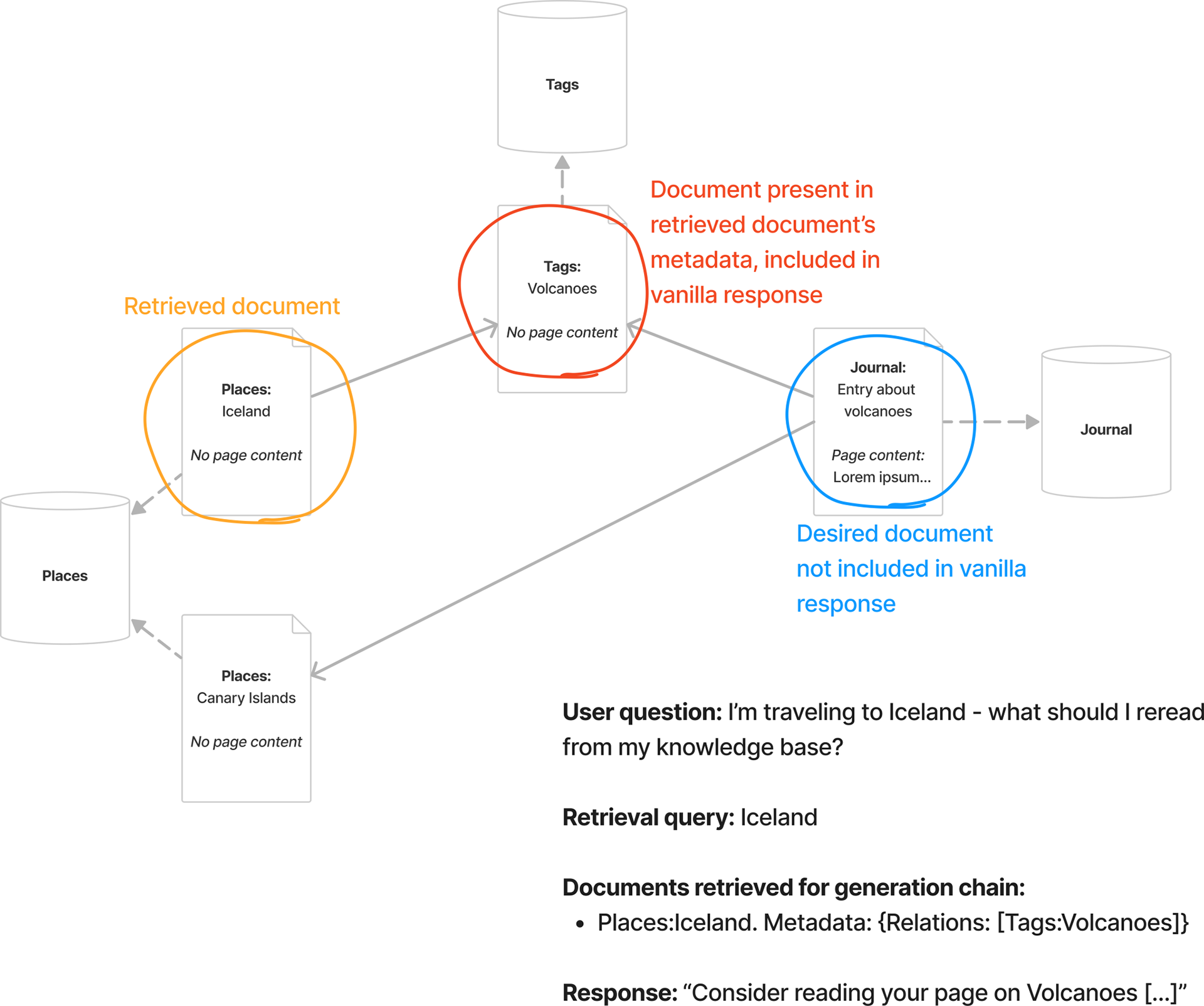
How can we make sure that the generation chain has that context? Here’s my little workaround. For metadata-only pages, like Tags and Places, I flatten their metadata, crucially including relations, into a string, and treat that as the page content that’s embedded and indexed. This provides a crude but functional solution: the retrieval chain is able to find not only the document “Iceland” but also “Volcanoes” (both in orange below), which now includes the string “Iceland” in its page content alongside all other relations. The generation chain, in turn, is now provided with the “Volcanoes” page and its relations, which include the desired document (in green below).
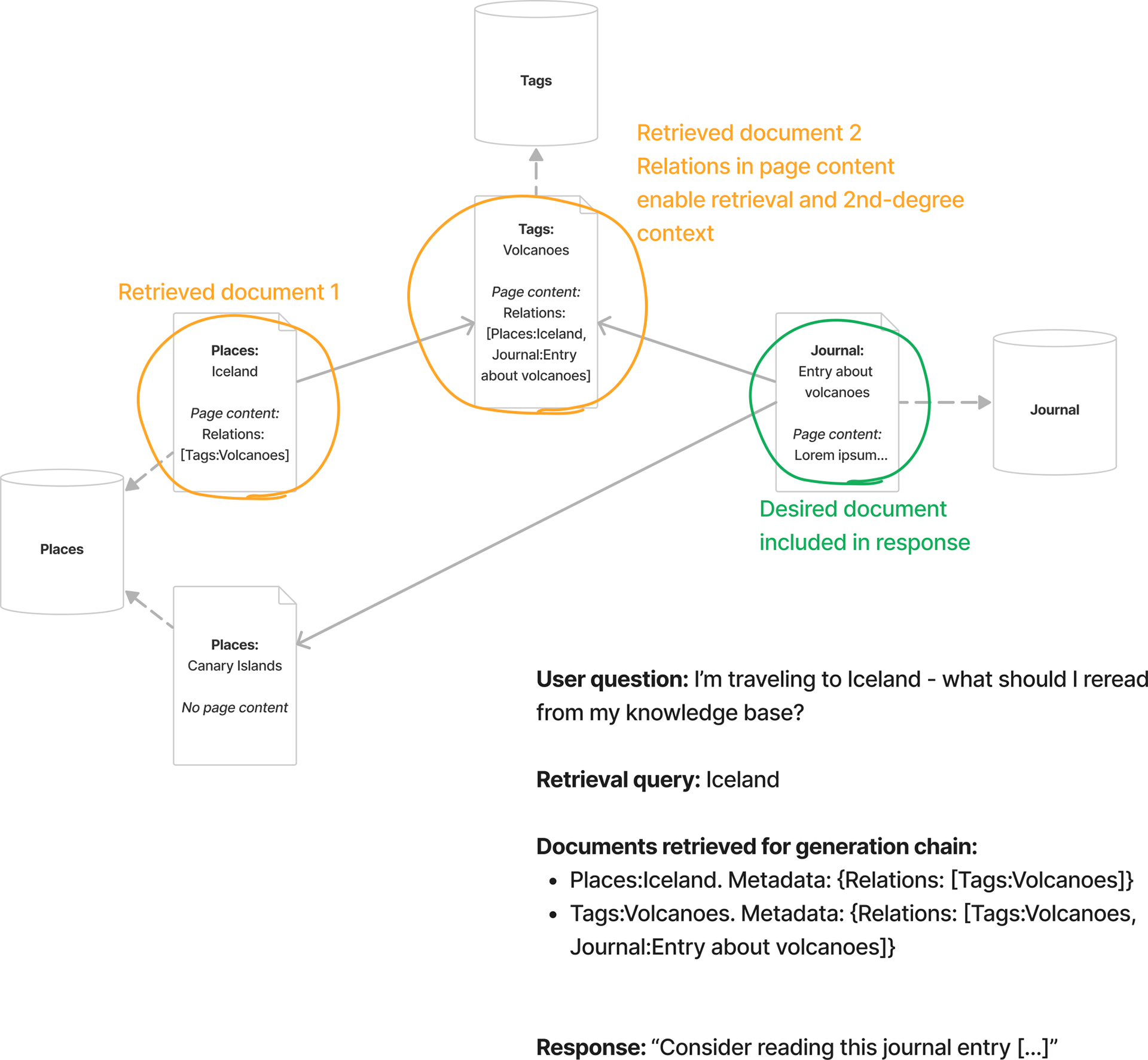
This approach is far from perfect: it muddles the embeddings of individual documents like “Iceland” and “Volcanoes” by including a lot of additional text in their page contents. It also struggles as the knowledge base becomes more densely connected, since the number of relations for a certain document can grow very quickly (for example, the Tags document “Artificial Intelligence” has 118 relations at the time of writing).
Final thoughts
This first version of Stevens has been a valuable lesson in the process of building AI-powered tools. I’m amazed by how easy it is to engineer complex workflows that allow us to interact with vast and multiform data in simple and abstract ways. Mainly, though, I’m happy that I’ve remained pragmatic throughout the process, and focused on shipping something imperfect that I can get my hands on quickly and start testing. Learning is pushing the point at which you start doing hacky workarounds—two weeks ago, I had no idea what RAG was, so getting to the point where flattening metadata into page contents is a hacky solution within reach, despite not being an elegant solution in the long term, is a satisfying measure of progress and, a pointer towards what to learn next.
A few things I’d like to work on include improving the way Stevens handles second-degree connections (the hacky workaround explained above is problematic both in concept and in practice), enhancing Stevens’s conversational memory to be able to improve results through multiple interactions, and ultimately, giving him a more explicitly agentic structure: giving him a set of tools and allowing him to decide, with every user input, whether to run a simple retrieval job as outlined above, think of related topics and retrieve documents for each of them, or perhaps search the web.